原文摘要
Released last night, Grok 4 is now available via both API and a paid subscription for end-users.
Update: If you ask it about controversial topics it will sometimes search X for tweets "from:elonmusk"!
Key characteristics: image and text input, text output. 256,000 context length (twice that of Grok 3). It's a reasoning model where you can't see the reasoning tokens or turn off reasoning mode.
xAI released results showing Grok 4 beating other models on most of the significant benchmarks. I haven't been able to find their own written version of these (the launch was a livestream video) but here's a TechCrunch report that includes those scores. It's not clear to me if these benchmark results are for Grok 4 or Grok 4 Heavy.
I ran my own benchmark using Grok 4 via OpenRouter (since I have API keys there already).
llm -m openrouter/x-ai/grok-4 "Generate an SVG of a pelican riding a bicycle" \
-o max_tokens 10000

I then asked Grok to describe the image it had just created:
llm -m openrouter/x-ai/grok-4 -o max_tokens 10000 \
-a https://static.simonwillison.net/static/2025/grok4-pelican.png \
'describe this image'
Here's the result. It described it as a "cute, bird-like creature (resembling a duck, chick, or stylized bird)".
The most interesting independent analysis I've seen so far is this one from Artificial Analysis:
We have run our full suite of benchmarks and Grok 4 achieves an Artificial Analysis Intelligence Index of 73, ahead of OpenAI o3 at 70, Google Gemini 2.5 Pro at 70, Anthropic Claude 4 Opus at 64 and DeepSeek R1 0528 at 68.
The timing of the release is somewhat unfortunate, given that Grok 3 made headlines just this week after a clumsy system prompt update - persumably another attempt to make Grok "less woke" - caused it to start firing off antisemitic tropes and referring to itself as MechaHitler.
My best guess is that these lines in the prompt were the root of the problem:
- If the query requires analysis of current events, subjective claims, or statistics, conduct a deep analysis finding diverse sources representing all parties. Assume subjective viewpoints sourced from the media are biased. No need to repeat this to the user.
- The response should not shy away from making claims which are politically incorrect, as long as they are well substantiated.
If xAI expect developers to start building applications on top of Grok they need to do a lot better than this. Absurd self-inflicted mistakes like this do not build developer trust!
As it stands, Grok 4 isn't even accompanied by a model card.
Update: Ian Bicking makes an astute point:
It feels very credulous to ascribe what happened to a system prompt update. Other models can't be pushed into racism, Nazism, and ideating rape with a system prompt tweak.
Even if that system prompt change was responsible for unlocking this behavior, the fact that it was able to speaks to a much looser approach to model safety by xAI compared to other providers.
Grok 4 is competitively priced. It's $3/million for input tokens and $15/million for output tokens - the same price as Claude Sonnet 4. Once you go above 128,000 input tokens the price doubles to $6/$30 (Gemini 2.5 Pro has a similar price increase for longer inputs). I've added these prices to llm-prices.com.
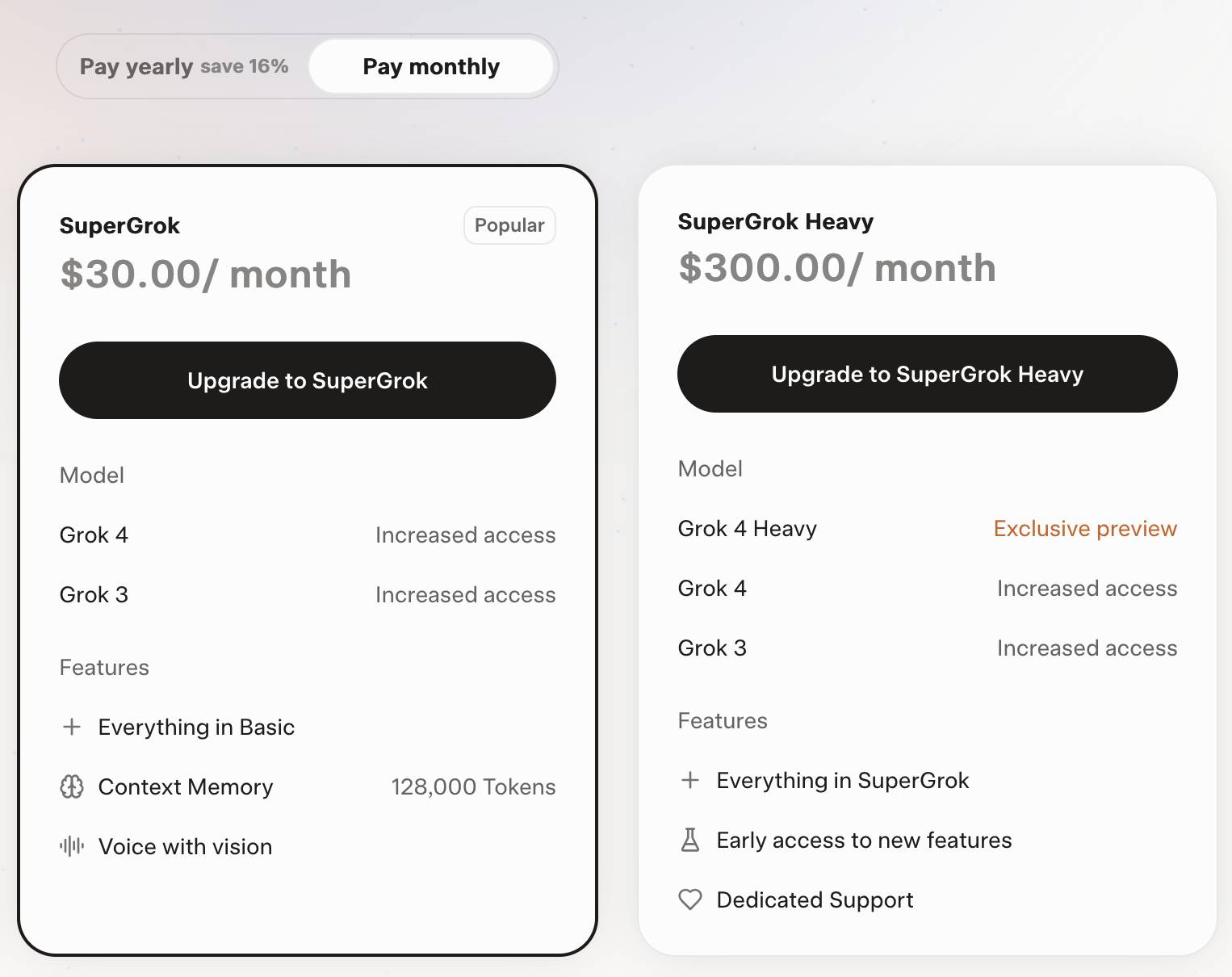
Consumers can access Grok 4 via a new $30/month or $300/year "SuperGrok" plan - or a $300/month or $3,000/year "SuperGrok Heavy" plan providing access to Grok 4 Heavy.
Tags: ai, generative-ai, llms, vision-llms, llm-pricing, pelican-riding-a-bicycle, llm-reasoning, grok, ai-ethics, llm-release, openrouter
[原文链接](https://simonwillison.net/2025/Jul/10/grok-4/#atom-everything)