原文摘要
Colossal new open weights model release today from Moonshot AI, a two year old Chinese AI lab with a name inspired by Pink Floyd’s album The Dark Side of the Moon.
My HuggingFace storage calculator says the repository is 958.52 GB. It's a mixture-of-experts model with "32 billion activated parameters and 1 trillion total parameters", trained using the Muon optimizer as described in Moonshot's joint paper with UCLA Muon is Scalable for LLM Training.
I think this may be the largest ever open weights model? DeepSeek v3 is 671B.
I created an API key for Moonshot, added some dollars and ran a prompt against it using my LLM tool. First I added this to the extra-openai-models.yaml file:
- model_id: kimi-k2
model_name: kimi-k2-0711-preview
api_base: https://api.moonshot.ai/v1
api_key_name: moonshot
Then I set the API key:
llm keys set moonshot
# Paste key here
And ran a prompt:
llm -m kimi-k2 "Generate an SVG of a pelican riding a bicycle" \
-o max_tokens 2000
(The default max tokens setting was too short.)
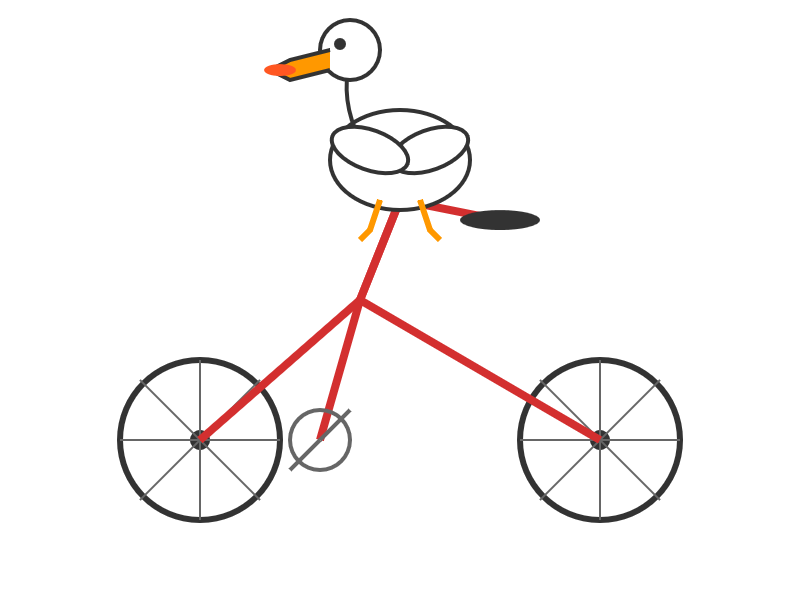
This is pretty good! The spokes are a nice touch. Full transcript here.
This one is open weights but not open source: they're using a modified MIT license with this non-OSI-compliant section tagged on at the end:
Our only modification part is that, if the Software (or any derivative works thereof) is used for any of your commercial products or services that have more than 100 million monthly active users, or more than 20 million US dollars (or equivalent in other currencies) in monthly revenue, you shall prominently display "Kimi K2" on the user interface of such product or service.
Update: MLX developer Awni Hannun reports:
The new Kimi K2 1T model (4-bit quant) runs on 2 512GB M3 Ultras with mlx-lm and mx.distributed.
1 trillion params, at a speed that's actually quite usable
<p><small></small>Via <a href="https://news.ycombinator.com/item?id=44533403">Hacker News</a></small></p>
<p>Tags: <a href="https://simonwillison.net/tags/ai">ai</a>, <a href="https://simonwillison.net/tags/generative-ai">generative-ai</a>, <a href="https://simonwillison.net/tags/llms">llms</a>, <a href="https://simonwillison.net/tags/llm">llm</a>, <a href="https://simonwillison.net/tags/mlx">mlx</a>, <a href="https://simonwillison.net/tags/pelican-riding-a-bicycle">pelican-riding-a-bicycle</a>, <a href="https://simonwillison.net/tags/llm-release">llm-release</a></p>
进一步信息揣测
- 模型规模与硬件需求:Kimi-K2模型(1万亿参数)在4位量化后,可在2台配备512GB内存的M3 Ultra芯片上通过mlx-lm和mx.distributed运行,且速度“实际可用”。这表明大规模模型的高效部署需要顶级硬件支持,但通过量化技术可显著降低资源消耗。
- 商业许可陷阱:虽然采用“修改版MIT许可证”,但附加条款要求月活超1亿或月收入超2000万美元的产品必须在前端标注“Kimi K2”。这种限制可能影响企业商业化决策,需警惕类似许可证的隐性合规成本。
- API使用技巧:默认的
max_tokens设置可能不足,需手动调整(如增至2000)以获得完整输出。这反映了第三方API的默认配置可能未优化实际场景,用户需主动调试参数。 - 模型训练优化内幕:采用与UCLA联合提出的Muon优化器(论文支持),暗示其训练效率可能优于传统方法,但具体实现细节未公开,需依赖论文或内部文档进一步研究。
- 非开源风险:尽管是“开放权重”,但许可证修改和代码未公开,实际仍属黑箱。行业内部常通过此类方式规避完全开源,同时限制竞争对手使用。
- 资源成本隐性提示:模型仓库大小达958.52GB,下载和存储需极高带宽与磁盘空间,隐含部署此类模型的基建门槛,小型团队可能面临挑战。
- 社区快速验证:开发者通过HuggingFace存储计算工具和简易API测试迅速评估模型性能,反映开源生态中工具链对降低试错成本的关键作用。