原文摘要
There's been a lot of excitement about whether frontier LLMs can replace existing document processing solutions altogether. We think about this a lot! TLDR:
- Accuracy gaps remain: Screenshot-only LLM parsing still hallucinates values and misses complex structures, especially in dense documents
- Missing enterprise metadata: Raw LLM APIs don't provide confidence scores, bounding boxes, or citations needed for production workflows
- High maintenance burden: Building and maintaining prompts across document types becomes a full parsing solution anyway
- Operational challenges: Rate limits, content filtering, and unpredictable costs break at enterprise scale
LlamaCloud was built to address these gaps. Read on for the full details.
Can we just rely on screenshots?
The baseline approach sounds simple: screenshot the page, feed it to your favorite LLM API (OpenAI, Claude, Gemini), and voilà! With models like Gemini 2.5 Pro and Claude Sonnet 4.0 showing impressive visual capabilities, many developers are asking: why build or buy a dedicated parsing solution when I can just call the LLM directly?
Traditional OCR solutions are certainly becoming obsolete because LLMs are dramatically better. But no, relying on raw LLM APIs alone won't get you a production-ready document processing pipeline that you can deploy across enterprise use cases:
- There’s still lots of accuracy problems
- The price per performance is not good enough
- There’s a lot of useful metadata, from confidence scores to bounding boxes, that will be missing.
- There’s a huge human cost to maintaining prompts/context and ensuring it generalizes to more use cases.
You still need a dedicated parsing solution, beyond basic LLM API calls, if you want high-quality context for any production AI agent use case - whether that’s a deep researcher or an automated workflow.
1. Frontier Models are good, but remain cost-prohibitive
The baseline of one-shot document parsing through screenshotting using the latest models has gotten much better in the past year, particularly over “standard” documents. However, they still fall short over a long-tail of edge cases.
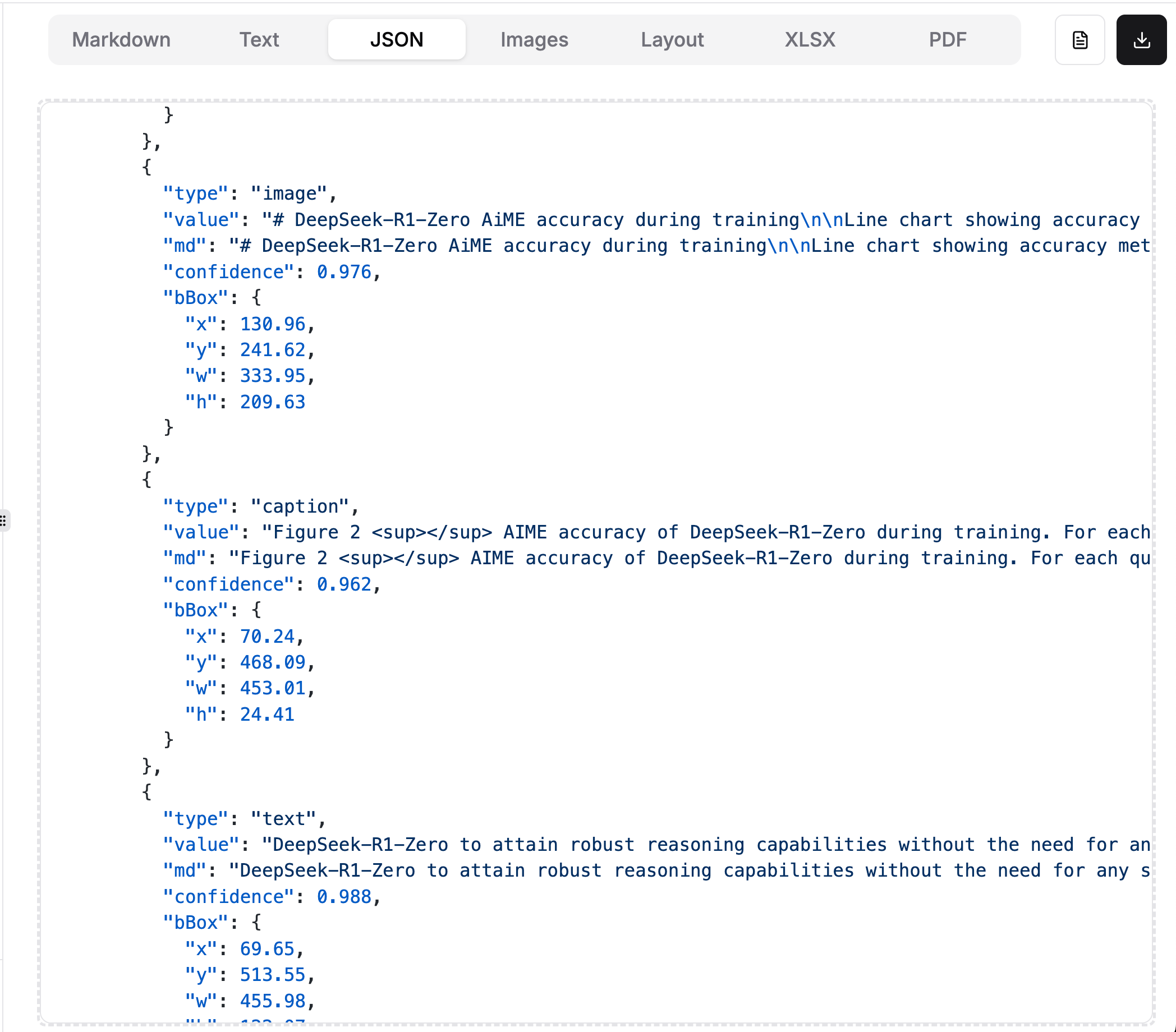
Screenshotting Loses Critical Information: Vision models working from page screenshots miss layered text, embedded metadata, and complex structures that are directly accessible in the file binary. Even the most advanced models struggle with complex charts where the values are directly within the file binary, complex tables with merged cells, and small text.
Check out the example below, specifically a screenshot of a graph from an equity research report. When we screenshot this and feed it into Claude Sonnet 4.0 to “parse this document into markdown”, it makes a best-effort attempt but still hallucinates the values (an easy giveaway: there are no negative numbers in the Claude-parsed table). In contrast, when we still use Sonnet models but combine it with existing text-based parsing techniques, we get much better results - this is what is enabled under LlamaCloud Premium mode!
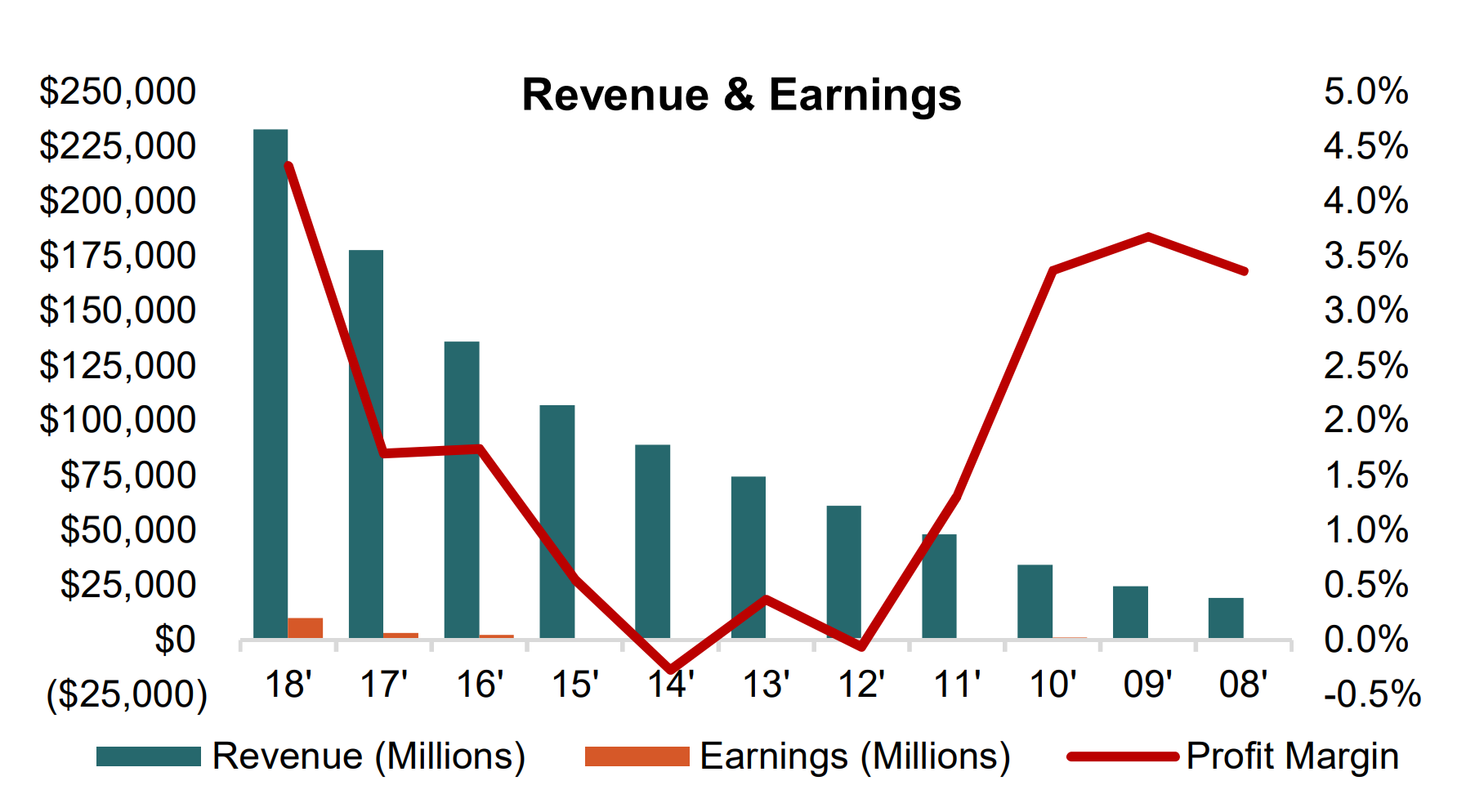
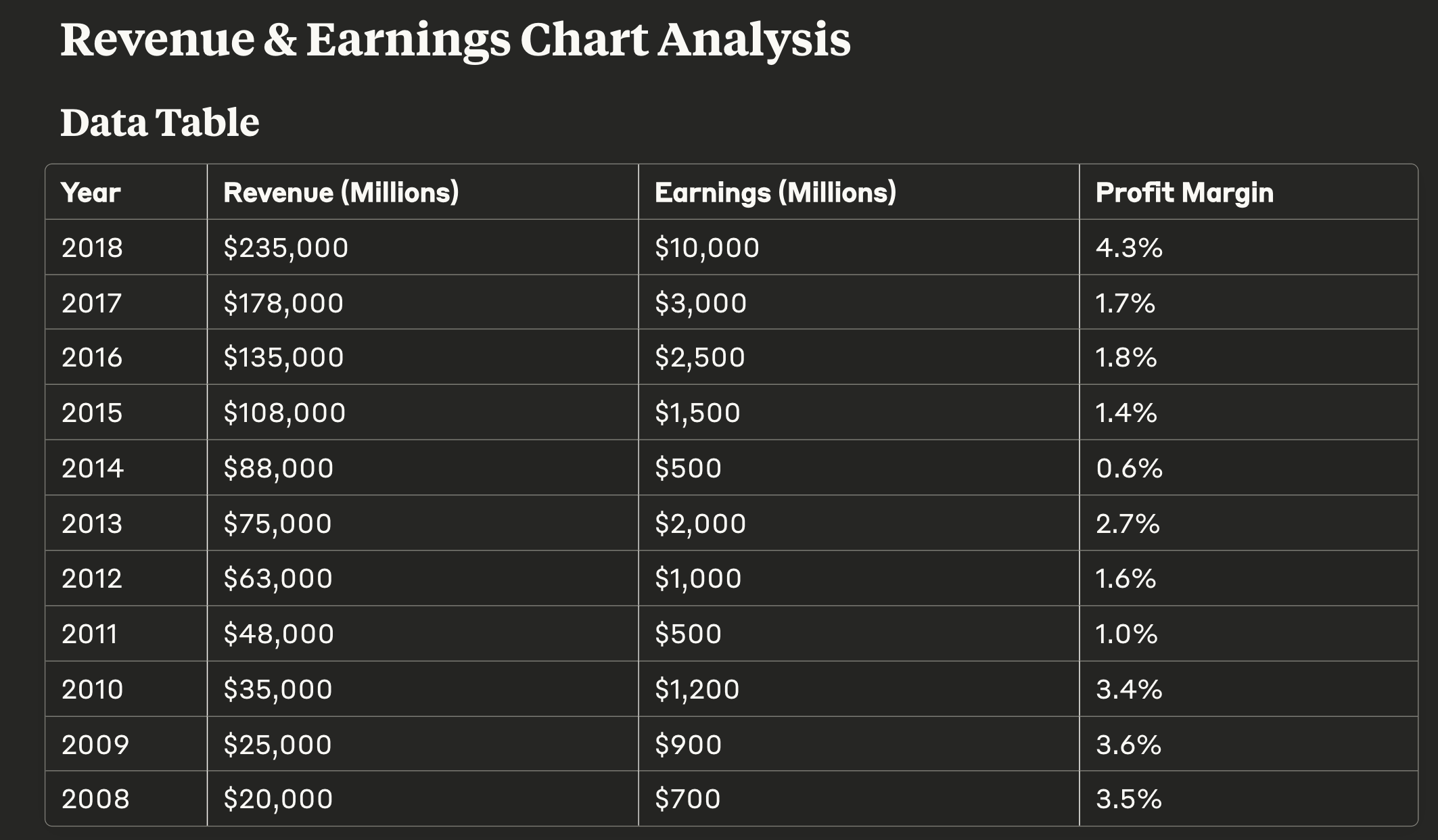
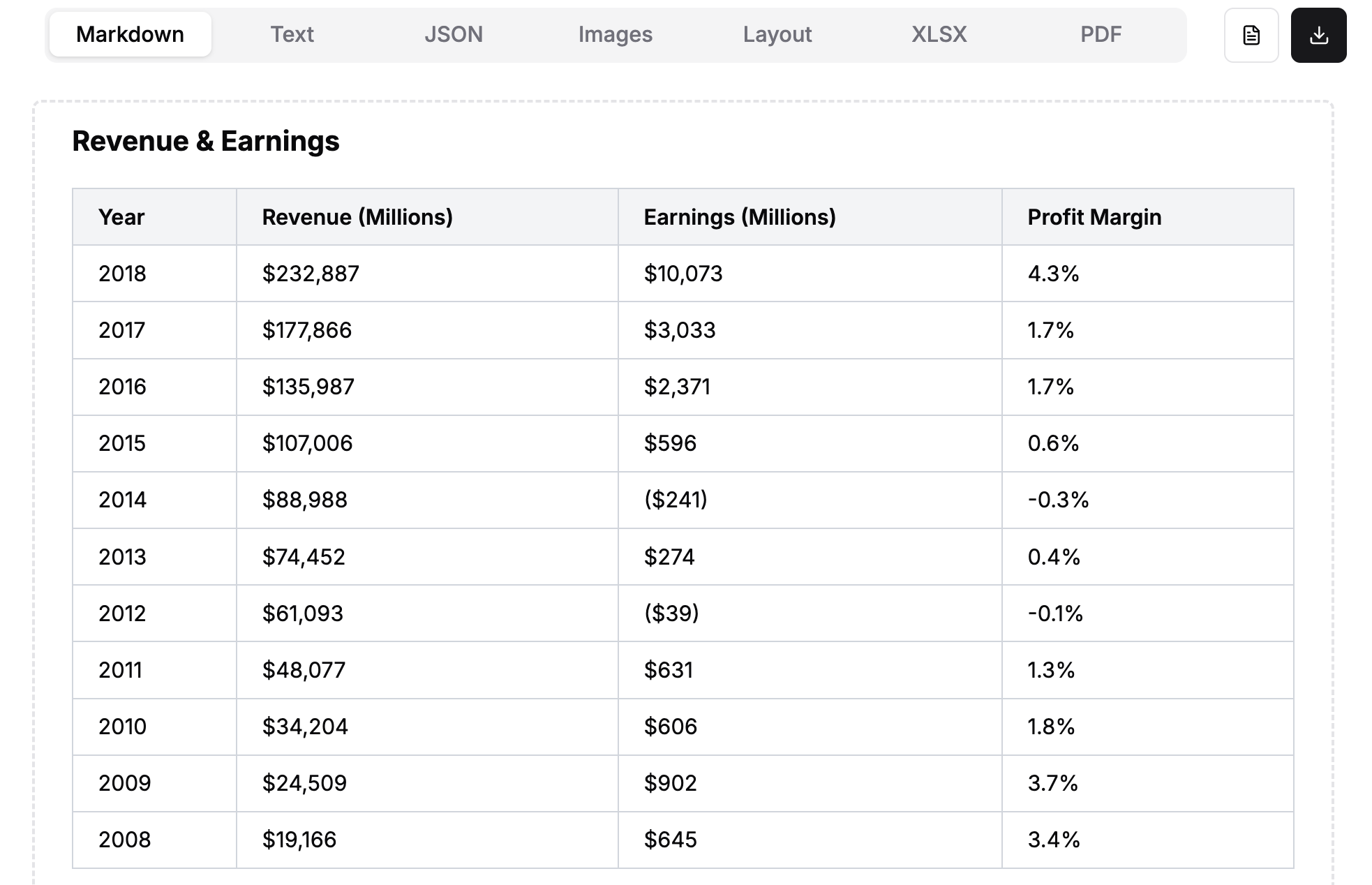
In general, the content density of your document matters. When you screenshot a very information-dense page, for instance one with a lot of embedded diagrams, visuals, and tables, LLMs/LVMs will often struggle to give you back the full information. This is both because most Chat UIs will natively resize the image to a lower resolution but also because LVMs will still drop content over high-resolution images.
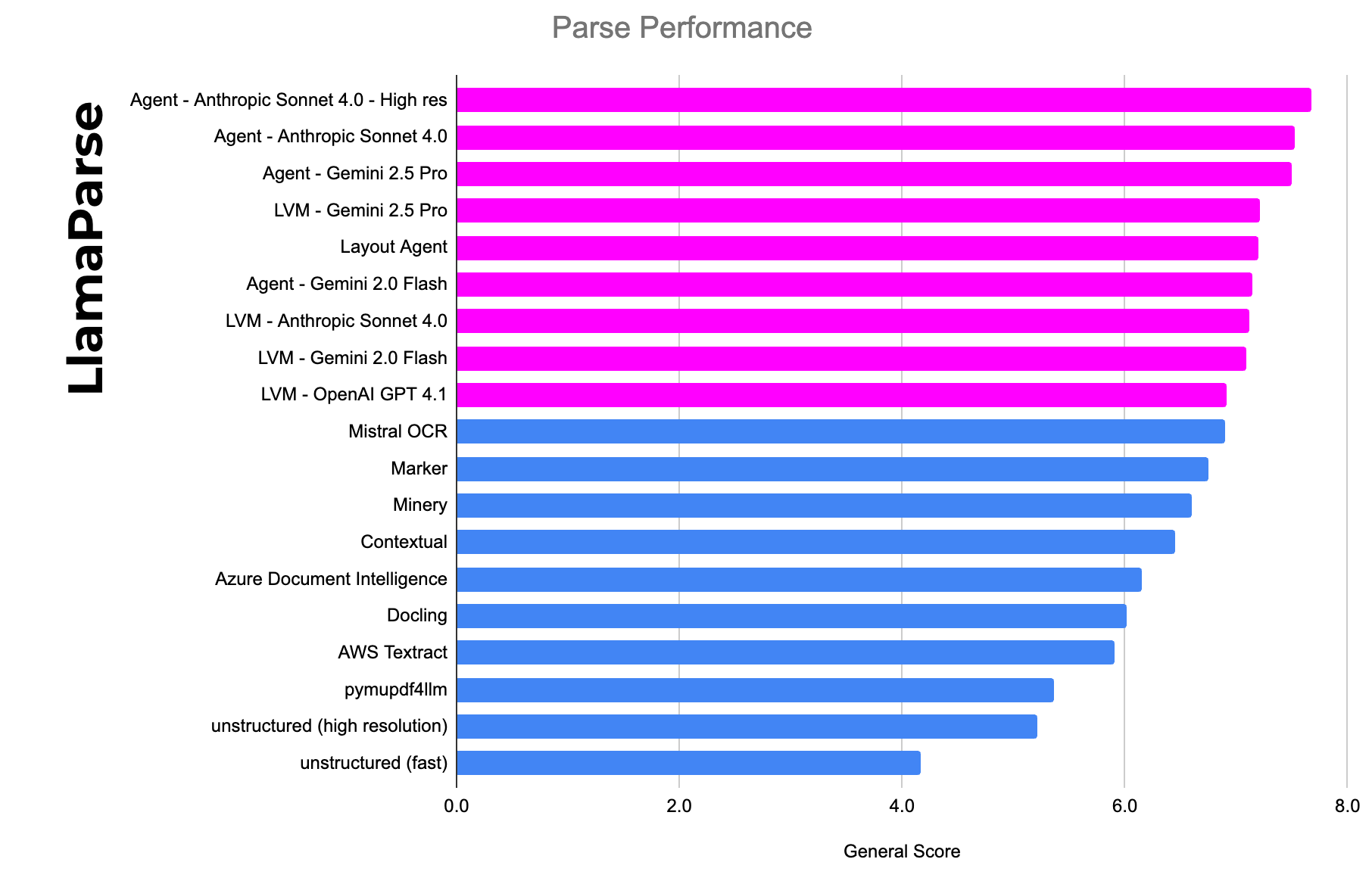
LlamaCloud lets you integrate with frontier models while solving both accuracy and cost concerns:
- In our “agent” modes, we extract layered text and metadata when available, then enhance it with vision models for layout reconstruction and OCR. This hybrid approach consistently outperforms screenshot-only methods. Our benchmarks (see below) generally show a 5%+ accuracy improvement vs. using the raw model.
- We’ve also invested in cheaper modes that just use LLMs (not LVMs) for a significant cost reduction on any page with simpler text/tables. We’ve also invested in an “auto-mode” that lets users save cost by using our cheapest parsing mode by default, and upgrading automatically to more advanced modes only when tricky document features are encountered.
2. You're Missing Enterprise-Critical Metadata
If all you get from an LLM API is a markdown blob or basic JSON, that might work for a toy demo. But for enterprise workflows where humans review outputs or decisions flow downstream, metadata is essential.
Screenshot-only approaches give you none of this. And if you've ever tried reverse-engineering bounding boxes or confidence scores from raw Claude or Gemini outputs, you know it's a fragile, vendor-specific mess.
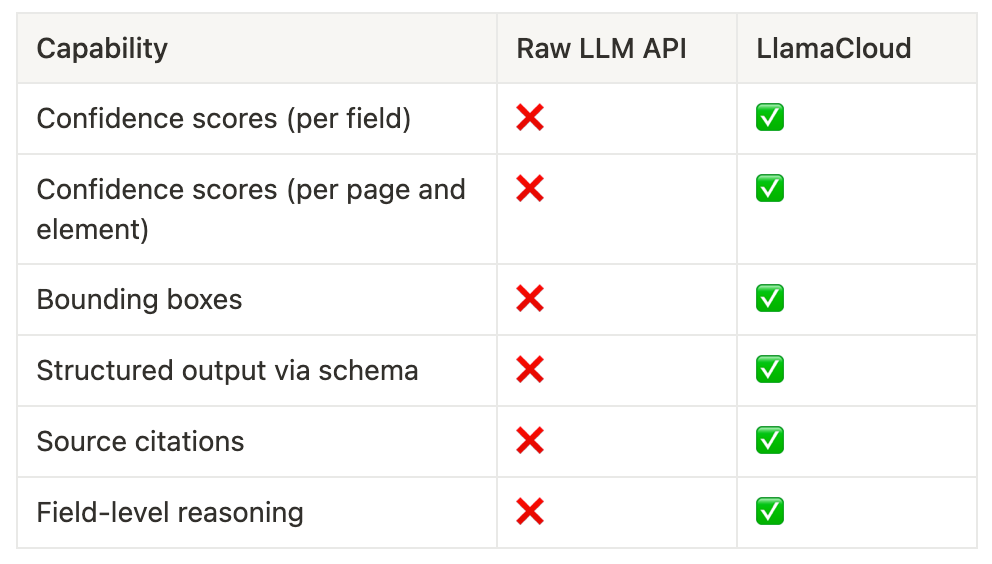
Confidence Scores and Quality Indicators: Production systems need to know how confident the model is about each extracted piece of information. This enables human-in-the-loop workflows where low-confidence extractions get manual review, quality control in automated pipelines, and performance monitoring over time.
Bounding Boxes and Source Citations: Enterprise applications need pixel-level bounding boxes for each extracted field, page references and exact text matches for audit trails, and visual citations that users can verify against the original document.
Structured Layout and Reasoning Information: Beyond just extracting text, enterprise applications need document hierarchy and section organization, table structures with preserved relationships, and reasoning explanations for each extracted field.
LlamaCloud comes with a lot of this information out of the box:
- Confidence scores for parsing and extraction (about to be released)
- Native layout detection with bounding boxes
- Citations and reasoning on every extracted field
- [Upcoming] A lot of exciting information in the works, including stylistic information!
![]()
3. Do you really want to Context Engineer a Document Parser?
The hottest new AI Engineering skill to learn these days is context engineering. Any LLM is only as good as the prompt/context/workflow you give it. One of the biggest issues with the "DIY Parsing through Screenshots" approach is the ongoing human effort required to maintain the prompts, tune it to generalize to more document types, and have it operate at scale.
You're Building a Parser Anyway
Even if your screenshot-to-LLM method works for one document type, what happens when you need to handle 10 new document types with different layouts? Schema changes that break your existing prompts? New teams that need different output formats?
At some point, you'll be maintaining templated prompts, implementing JSON parsing logic, building retry mechanisms for hallucinated outputs, and testing model-specific quirks. At that point—you're building a document parsing solution.
Standardization Across Teams
Enterprise organizations need consistent approaches that work across teams and use cases. Every team building their own LLM-based parsing means inconsistent output formats, duplicated effort on common document types, and higher maintenance burden as model APIs evolve.
LlamaCloud provides a standardized schema interface: define your extraction schema once (via JSON Schema or Pydantic), and our backend handles prompt optimization, output formatting, validation, and retries across multiple model providers.
4. Operational Challenges That Break at Scale
Hitting LLM APIs directly introduces operational headaches that become critical bottlenecks at enterprise scale.
Rate Limiting and Latency: Vision models have strict rate limits and high per-call latency (5-20+ seconds per page). Processing hundreds or thousands of documents requires sophisticated queue management and retry logic.
Content Filtering Issues: Many LLM APIs have content filters that inappropriately flag legitimate business documents containing financial data, legal terms, or technical specifications—causing processing failures.
Reliability and Vendor Risk: When the LLM service goes down, your entire document processing pipeline stops. API changes can break your prompts without warning.
Unpredictable Costs: LLM API pricing for vision models can be expensive and unpredictable, especially for high-resolution document images.
LlamaCloud handles all of this with per-page caching and deduplication, configurable processing modes for cost optimization, async processing with webhooks for large document volumes, and credits-based pricing for cost predictability.
The LlamaCloud Approach: Best of Both Worlds
We absolutely agree with the thesis that LLMs have made traditional OCR obsolete. But the path forward isn't replacing your parsing infrastructure with raw API calls—it's using a platform that harnesses the latest LLMs while solving the enterprise-scale challenges outlined above.
LlamaCloud wraps frontier models (GPT-4.1, Claude Sonnet 4.0, Gemini 2.5 Pro) with always-updated intelligence, rich metadata by default, production-grade reliability, optimized prompts, and predictable economics.
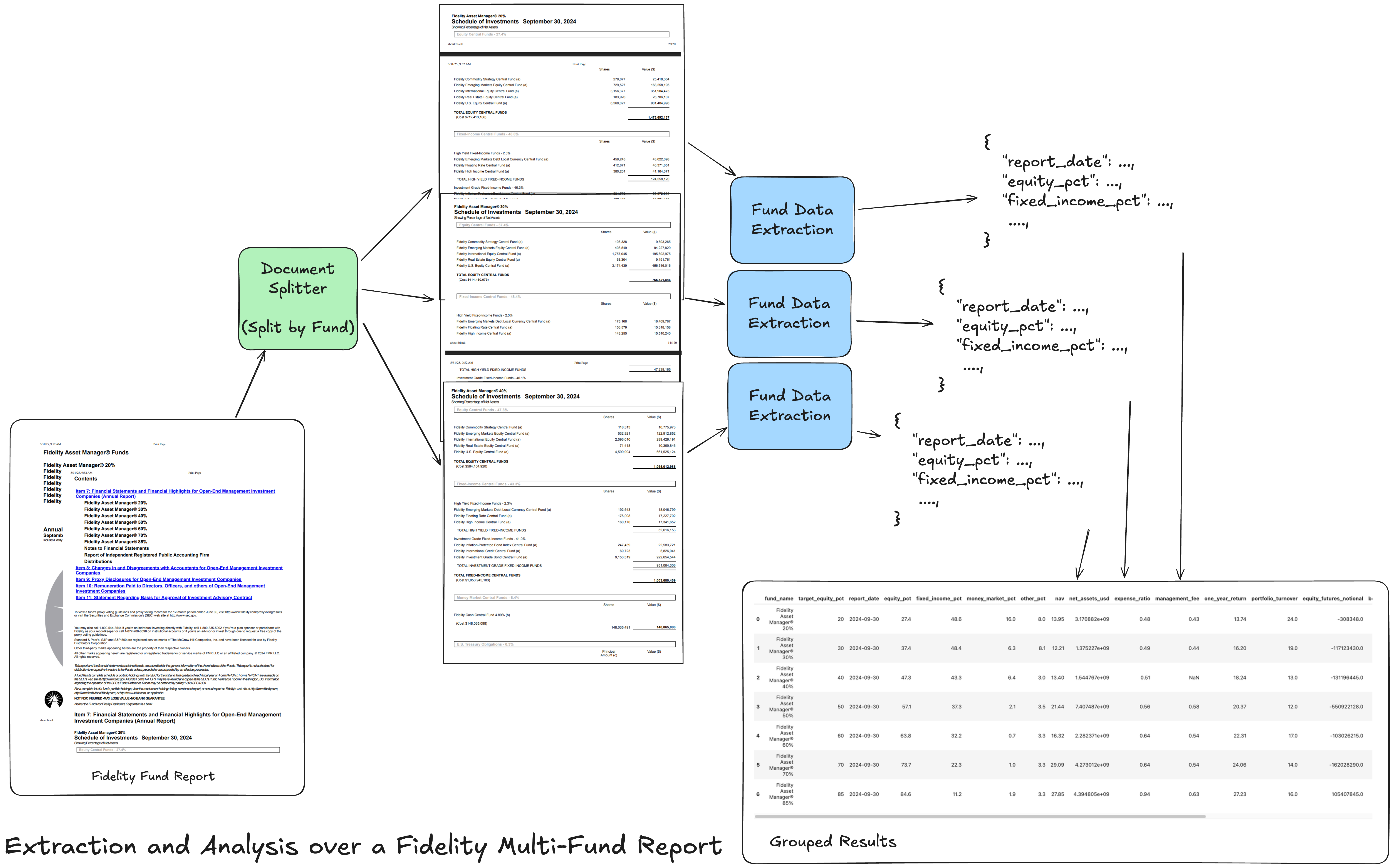
[Bonus] Beyond Parsing, Come Build E2E Document Workflows!
Most document-related knowledge work requires multiple steps beyond basic text extraction: structured field extraction from invoices or contracts, source attribution for compliance and audit trails, document classification for routing workflows, and downstream integration with search or agent systems.
We have a ton of examples showing you how to interleave LlamaCloud with our agentic workflow orchestration. These agent workflows involve interleaving parsing, extraction, retrieval with LLM calls in a sequential or looping manner. Because they are multi-step, high parsing and extraction accuracy become even more important (the probability of failures increases the more steps there are), and metadata is also important - you ideally want to be able to trace confidence scores and citations through to the final output!
The Bottom Line
The future of document processing is absolutely LLM-powered, but the winning approach combines the intelligence of frontier models with the operational excellence, metadata richness, and engineering sophistication that enterprise applications require.
Just as you wouldn't replace your database with direct file system calls, you shouldn't replace your document processing infrastructure with unstructured LLM API calls. The abstraction layer matters—it's where reliability, observability, and long-term maintainability are built.
You can always build it yourself—you just have to handle prompting, retries, metadata extraction, schema enforcement, API error handling, bounding box recovery, multi-model fallbacks, and more.
If you want this handled for you though, there’s always LlamaCloud. Come check it out!
- Sign up to LlamaCloud (get 10k free credits)
- Come get in touch
进一步信息揣测
- 前沿LLM的视觉解析存在隐性缺陷:即使使用Claude Sonnet 4.0等顶级模型,仅通过截图解析文档仍会虚构数据(如表格中的负数值),且无法处理合并单元格、复杂图表或小字体等长尾场景。
- 企业级元数据缺失是硬伤:直接调用LLM API无法获取生产环境必需的置信度分数、文本边界框和引用来源,这些需依赖传统解析技术补充(如LlamaCloud的Premium模式)。
- 隐藏的维护成本:看似简单的prompt工程实际需要持续优化以覆盖多文档类型,最终演变为需专职团队维护的完整解析系统,隐性人力成本远超预期。
- 规模化的运营陷阱:企业级应用中,LLM API的速率限制、内容过滤规则和不可预测的计费模式(如高密度文档处理成本激增)会导致系统崩溃。
- 二进制文件的隐藏优势:截图会丢失文件底层嵌入的层级文本和元数据(如PDF中的图表原始数据),而直接解析二进制文件能保留这些关键信息,此差异极少被公开讨论。
- 付费服务的真实价值:LlamaCloud等专业解决方案的核心优势在于混合解析技术(结合LLM与传统OCR),但行业通常只宣传LLM能力,对传统技术的增效作用避而不谈。
- 模型选型的潜规则:尽管Gemini 2.5 Pro等模型宣传视觉能力强,实际测试中复杂文档的解析仍依赖特定模型+定制管道的组合,单一模型无法通吃所有场景。
- 置信度分数的黑箱操作:企业级文档处理要求每个输出值附带可信度评分,但主流LLM API不提供此功能,迫使开发者自行搭建后处理校验层。