原文摘要
Yesterday was Qwen3-30B-A3B-Instruct-2507. Qwen are clearly committed to their new split between reasoning and non-reasoning models (a reversal from Qwen 3 in April), because today they released the new reasoning partner to yesterday's model: Qwen3-30B-A3B-Thinking-2507.
I'm surprised at how poorly this reasoning mode performs at "Generate an SVG of a pelican riding a bicycle" compared to its non-reasoning partner. The reasoning trace appears to carefully consider each component and how it should be positioned... and then the final result looks like this:
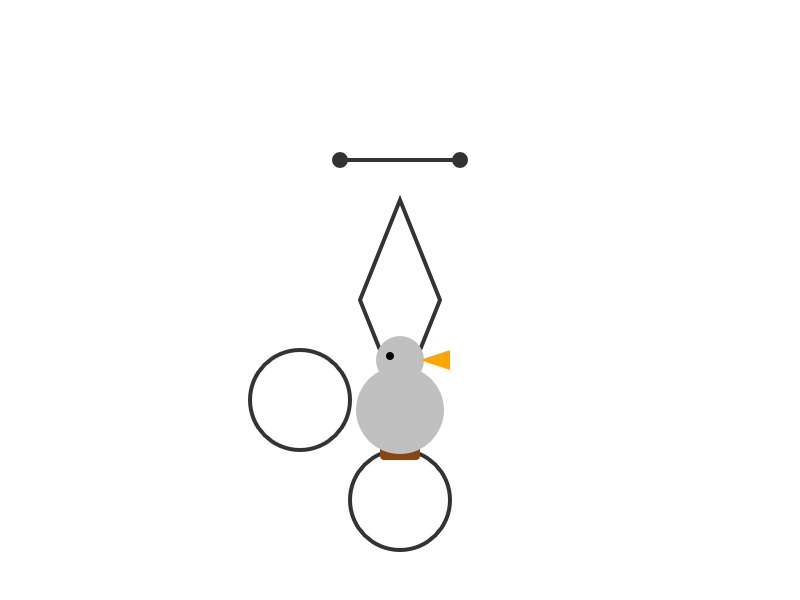
I ran this using chat.qwen.ai/?model=Qwen3-30B-A3B-2507 with the "reasoning" option selected.
I also tried the "Write an HTML and JavaScript page implementing space invaders" prompt I ran against the non-reasoning model. It did a better job in that the game works:
It's not as playable as the on I got from GLM-4.5 Air though - the invaders fire their bullets infrequently enough that the game isn't very challenging.
This model is part of a flurry of releases from Qwen over the past two 9 days. Here's my coverage of each of those:
- Qwen3-235B-A22B-Instruct-2507 - 21st July
- Qwen3-Coder-480B-A35B-Instruct - 22nd July
- Qwen3-235B-A22B-Thinking-2507 - 25th July
- Qwen3-30B-A3B-Instruct-2507 - 29th July
- Qwen3-30B-A3B-Thinking-2507 - today
<p><small></small>Via <a href="https://x.com/Alibaba_Qwen/status/1950570969036361799">@Alibaba_Qwen</a></small></p>
<p>Tags: <a href="https://simonwillison.net/tags/ai">ai</a>, <a href="https://simonwillison.net/tags/generative-ai">generative-ai</a>, <a href="https://simonwillison.net/tags/llms">llms</a>, <a href="https://simonwillison.net/tags/qwen">qwen</a>, <a href="https://simonwillison.net/tags/pelican-riding-a-bicycle">pelican-riding-a-bicycle</a>, <a href="https://simonwillison.net/tags/llm-reasoning">llm-reasoning</a>, <a href="https://simonwillison.net/tags/llm-release">llm-release</a>, <a href="https://simonwillison.net/tags/ai-in-china">ai-in-china</a></p>
进一步信息揣测
- Qwen模型的分拆策略调整:Qwen团队在4月发布的Qwen3中并未区分推理与非推理模型,但近期突然调整策略,将模型明确分为推理(Thinking)和非推理(Instruct)版本,可能反映内部对模型能力定位的重新评估或用户反馈驱动的迭代。
- 推理模型的局限性:尽管Qwen3-30B-A3B-Thinking-2507在生成SVG等任务中表现出详细的推理过程(如分析组件布局),但实际输出质量极差(如“自行车”仅显示为线条和点),说明其推理逻辑与执行能力存在脱节,可能因训练数据或架构设计缺陷导致。
- 游戏开发能力的隐性差异:同一推理模型在编写“太空侵略者”游戏时表现优于SVG生成,但游戏可玩性仍逊于竞品GLM-4.5 Air(敌人攻击频率低),暗示模型在代码生成任务上的能力不均衡,可能依赖特定领域的微调数据。
- 高频发布的潜在动机:Qwen在9天内密集发布5款模型(包括不同参数规模和功能版本),可能意在快速抢占市场或测试用户对不同架构的反馈,但也可能暴露其版本迭代的试错性质,稳定性存疑。
- 模型命名规则隐含信息:版本号中的“A3B”“A22B”等后缀可能对应内部架构版本或训练批次,但未公开具体含义,需通过私下渠道或付费文档获取解读,属于行业内部知识壁垒。
- 中国AI团队的竞争策略:通过高频发布和细分功能模型(如专精代码的Qwen3-Coder),Qwen可能试图在开源生态中差异化竞争,但实际效果需依赖社区实测,非公开的基准测试数据可能更关键。
- 未公开的优化方向:模型在“推理”模式下表现不稳定(如SVG失败但游戏成功),可能反映团队优先优化了代码生成等实用场景,而艺术类任务被牺牲,这种权衡通常不会在官方文档中明确说明。